How to Organize Your Data Product Ecosystem
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.

A simple outcome-first framework for building data products that compound in value
Data products deliver reusability and compounding value. But most teams struggle with organization: what to build first, how data products should connect, what keeps an ecosystem coherent as it grows.
A quick recap: A data product is a reusable, discoverable, and governed entity that combines data, context, logic, and infrastructure to make information instantly ready for activation across BI tools, applications, and AI agents. A data product is not just clean data. It's a business capability with ownership, accountability, and measurable ROI.
The mistake most teams make: they start with sources instead of outcomes. They catalog Salesforce data, clean up event streams, build an inventory of available datasets. Six months later, they have a catalog nobody uses because it doesn't connect to business needs.
Or they build consumer data products without organizing principles. Three different data products all need clickstream data, so each team writes their own cleaning logic, validates fields differently, and defines 'active user' in their own way. The result: wasted effort in rebuilding what already existed, inconsistent data quality and conflicting key metrics like engagement numbers across the organization.
The difference between data product ecosystems that compound versus those that fragment comes down to understanding how different types of products depend on each other.
Source-aligned data products make sources reliable. Consumer-aligned data products deliver outcomes. Aggregates emerge when patterns repeat. Get these relationships right, and each product you build makes the next one easier.
This post gives you the organizing framework. By the end, you'll understand the different types of data products, what purpose each serves, and how to organize them so they compound in value from the start.
The Core Idea: Orientation
Each data product should be oriented around one of two things: a source or an outcome. That choice clarifies what the data product is for, who it serves, and how it should be designed.
As your catalog grows beyond the first few data products, this distinction becomes a useful check. It helps you spot duplicated effort, avoid building on unstable foundations, and understand how each data product fits into the broader ecosystem.
Data product ecosystems are generally built around three types of data products, each serving a different purpose:
Source-aligned data products: These deliver clean, governed data from source systems, making raw data from CRMs, ERPs, data warehouses, or event streams reliable and reusable.
Consumer-aligned data products: These solve specific business problems, delivering outcomes like Lead Scoring, Campaign Attribution, or Customer Segmentation to business users, applications, or dashboards.
Aggregate data products: These reduce duplication, emerging when multiple consumer-aligned data products need the same data, such as a complete customer profile.
Understanding how these three types connect is the key to building an ecosystem that compounds in value rather than proliferates in complexity. Let's look at each one.
Source-Aligned Data Products
Raw data from business systems isn't ready to use. It needs to be cleaned, validated, and governed before other data products can rely on it. A source-aligned data product takes raw data from a system and turns it into something trustworthy and usable. Consider a marketing team using Salesforce as their CRM. Salesforce generates account records, contact information, opportunity stages, activity logs, and custom field values. In its raw form, this data is messy. Field names are inconsistent across different teams. Some records are incomplete. Custom fields get added or modified as business needs change. A source-aligned data product for Salesforce CRM data would:
- Ingest the raw data
- Apply consistent naming and structure
- Add quality checks (are required fields populated? are dates valid?)
- Attach governance metadata (ownership, lineage, update frequency)
- Make it available for downstream consumption
Source-aligned data products are built for reusability. If three different consumer-aligned data products all need Salesforce data, you don't want each one building its own ingestion and cleaning logic. You productize the source once, and everyone benefits.
The audience for a source-aligned data product is other data products and data teams. Source-aligned data products serve as building blocks. When you build a consumer-aligned data product like Risk Profile, it pulls from multiple source-aligned data products rather than connecting directly to raw source systems. The Product Data and Customer Details source-aligned data products feed the Risk Profile data product, which then serves the business user. In the example above, you might build separate source-aligned data products like Product Data (from SAP), Customer Details (from Salesforce), Transaction History (from Databricks and Big Query), and User Behavior (from Google Analytics). Each is its own data product, representing one or more source systems that have been cleaned and governed, ready to feed downstream data products
Consumer-Aligned Data Products
A consumer-aligned data product exists to deliver a business outcome. It's oriented toward the person or system that needs to make a decision. Consider a Risk Profile data product. A financial team wants to prioritize customer risk levels for lending decisions, fraud detection, or compliance reporting. They need a score that reflects creditworthiness or potential exposure, based on transaction patterns, account history, and behavioral signals. A consumer-aligned data product for Risk Profile would:
- Pull from multiple source-aligned data products (Product Data and Transaction History)
- Apply business logic to calculate scores
- Deliver results in a format the consumer can use (API, dashboard, CRM integration)
- Meet an SLA that matches the business need (daily refresh? real-time?)
The audience for a consumer-aligned data product varies by context. Sometimes it's applications (a CRM surfacing lead scores to sales reps, a personalization engine calling an API). Sometimes it's AI agents (a copilot retrieving customer context to answer questions). Sometimes it's BI tools (Tableau powering a dashboard for marketing ops). And sometimes it's analysts or data scientists querying the data product directly for exploration or modeling.
What matters is the orientation toward outcomes: solving a specific problem rather than representing a source. Consumer-aligned data products might include Customer Intelligence 360, Lead Scoring, Campaign ROI Attribution, Customer Segmentation, Content Performance Analytics, and Predictive Conversion Insights. Unlike source-aligned data products, these aren't about making data from a system usable. They're about solving specific business problems.
The Relationship Between Source-aligned and Consumer-aligned Data Products
Here's where the model comes together. Consumer-aligned data products don't pull directly from raw sources. They pull from source-aligned data products. Why? Because raw sources are messy: inconsistent schemas, incomplete data, no quality checks, no governance. The source-aligned data product handles this complexity once. The consumer-aligned data product can then focus on business logic rather than wrestling with source data quality. It's not duplication, it's division of responsibility. Take Risk Profile as an example. It might need:
- Product Data (from a SAP Data Product)
- Transaction data across business divisions (from Databricks and Big Query Data Products)
Each source-aligned data product is doing its job: making a source reliable. The Risk Profile consumer-aligned data product combines them to deliver the outcome. This separation matters because:
1. Reusability. The same Transaction History Data Products can feed Risk Profile and Customer Intelligence 360. You're not rebuilding ingestion logic for each.
2. Clarity of ownership. The team owning the Product Data product focuses on data quality and freshness. The team owning Risk Profile data product focuses on risk assessment logic and business outcomes. Clear boundaries.
3. Easier to scale. When a new source is added, you just add the source-aligned data product and harmonize it to the consumer-aligned data product's structure. No rework is needed for downstream consumers.
Aggregate Data Products
As you build multiple consumer-aligned data products, you'll notice duplication. Several data products pulling from the same sources, doing the same joins, applying the same logic. That's when an aggregate data product makes sense. An aggregate data product combines multiple source-aligned products into a unified view that serves multiple downstream needs.
Consider Transaction History in the diagram below. It combines transaction data from multiple business divisions (Credit Card and Lending) into a unified aggregate. Multiple consumer data products like Risk Profile and Customer Intelligence 360 need this same combination of transaction data. Instead of each product pulling from both division-specific sources and doing the same joins, Transaction History provides that unified foundation once.
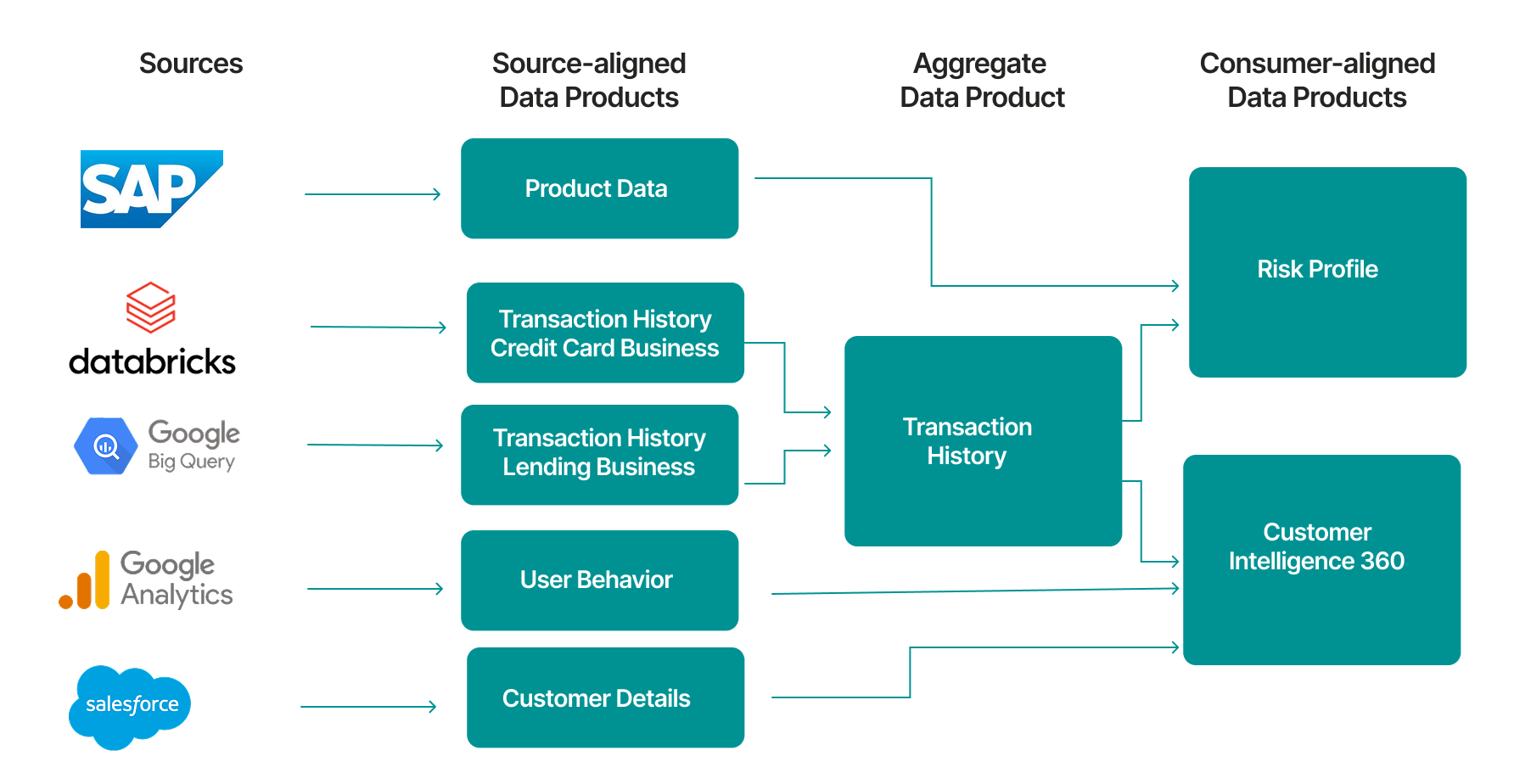
Aggregates don't get designed upfront. You don't plan them before you have consumer products. They reveal themselves. When you notice multiple consumer-aligned data products duplicating the same logic, that's a signal. The pattern has earned its place as a product. The audience for an aggregate data product is consumer-aligned products. Aggregate data products sit between sources and outcomes, reducing duplication and providing a stable, governed layer that multiple teams can depend on.
The Three Types of Data Products: A Quick Reference

Looking at Your Own Ecosystem
Now apply this to your situation. Start with the business outcomes. What decisions need to be made? What questions does the business keep asking? These point to what consumer-aligned data products you might need. Then trace backward to the sources. What systems hold the data those outcomes require? Which sources feed multiple use cases and would benefit from being productized once?
If you already have a few consumer-aligned products, look for duplication. Are they pulling from the same sources and doing similar joins? That signals an aggregate might be worth building. You don't need to build everything at once. But seeing the full picture helps you build intentionally. Each source-aligned product you create becomes an asset for future consumer-aligned products.
Common Pitfalls to Avoid
Use this checklist to diagnose your current state:
- All products are source-aligned; catalog has no consumers → Start with a business outcome; build a consumer-aligned data product first
- Consumer-aligned data products connect directly to raw systems → Introduce source-aligned data products; refactor dependencies
- Same term defined differently across products → Establish a shared glossary; products inherit definitions rather than inventing their own
- Aggregates planned upfront, sitting unused → Let aggregates emerge from observed patterns
- No visibility into product quality or usage → Instrument quality checks; track how products are consumed
Data products aren't just pipelines with better marketing. They're a way of organizing your data ecosystem around clear purposes and audiences. Source-aligned data products make sources reliable and reusable. Consumer-aligned data products deliver business outcomes. Aggregates emerge when patterns repeat across multiple products. When you understand these orientations, you can look at your own ecosystem and see not just what exists, but what's missing. You can structure your data products intentionally, with each one serving a clear role and connecting to the larger whole.
Implementing with DataOS
You don't need to build everything at once. But you do need infrastructure that supports this organizing principle. DataOS serves as the essential data foundation and AI activation layer for any data stack, transforming existing data infrastructure into contextualized data products that power critical operations and intelligent systems.
For Source-Aligned Data Products : DataOS transforms raw sources into source-aligned data products. Instead of building custom ingestion pipelines, quality checks, and governance for each source, you define the product declaratively and DataOS handles the implementation. The result is a productized source that multiple downstream products can depend on.
For Aggregate Data Products: DataOS orchestrates dependencies between data products. When Risk Profile needs to pull from Transaction History across multiple sources, they can be aggregated into one Data Product. Aggregation around data domains is the most common reason for aggregated data products.
For Consumer-Aligned Data Products: DataOS orchestrates dependencies between data products. When Risk Profile needs to pull from Product Data, Customer Details, Transaction History, and User Behavior, DataOS manages versioning and ensures consistency. Data products can be accessed through APIs, Power BI, Tableau, MCP, GraphQL, and more, ensuring they reach consumers in the format they need.
For the Full Ecosystem: DataOS maintains a catalog of all data products - what they contain, who owns them, how they're used, and how they connect. When you're building your third or fourth consumer-aligned data product, you can see what source-aligned data products already exist and what aggregates have emerged. You're building on a foundation, not starting from scratch each time.
This is how teams move from understanding the model to actually building reusable, scalable data product ecosystems.
Ready to build a data product ecosystem that compounds in value? Schedule a demo to see how DataOS can help.



